t-SNE as Human-Machine Translator
- lucreceshin
- Nov 21, 2020
- 3 min read
Updated: Jan 14, 2021
Let's say, your model performance is not up to your expectation. For example, a ResNet-50 model is not able to distinguish between two classes. You want to ask the model why it thinks an image of class A looks more like class B. How can you make the model answer the question? Yes, visualizations help a lot, and t-SNE is one of them. A star one.
Before, my first instinct after seeing poor performance was that the model was not complex enough. So I stepped it up to ResNet-101. Maybe doubled the number of filters. Did this help at all? Rarely. When it did help, I just brushed it up as "oh, the model architecture was too simple". This did not help me in understanding how the data was distributed OR how the model worked.
When we are left with a non-sensical output from a complex architecture like ResNet-50, we need to look inside it. That is, we need to look at the feature space. But this feature space is something like a dimension of 2048, isn't it? t-SNE is an effective tool to reduce such high-dimensional data into low-dimensional, usually 2-D, so you can visualize it. I feel that this kind of visualization tool is a bridge between a human and a machine, as it translates a machine's language (an uninterpretable 2048-dim vector) to a human's (clean 2-D visualizations).
To try out t-SNE, all you need to do is instantiate a t-SNE model using sklearn with the following code : sklearn.manifold.TSNE( n_components=2 ). Then, fit it to your data and transform your data using .fit() and .transform(). Let me show you how it translated my ResNet-50 model for me. I was working on a Domain Adaptation problem, where I used images of one domain (e.g. camera pictures) as training set and images of another domain (e.g. pencil drawings) as test set. Basically, I wanted to train a model that does not get affected by the shift of the domain. The resulting performance after first try looked like this:
Training Domain : Test Domain :

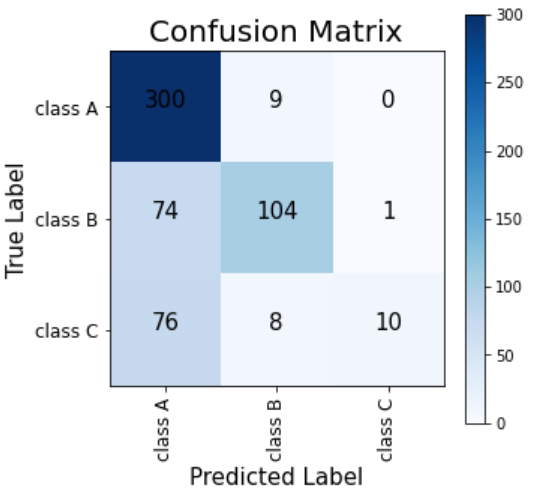
As you can see in the two confusion matrixes, although the training domain images had fairly good classification accuracies, in test domain, most of class C images were mis-classified as class A. After spending some frustrating hours asking myself why would the model do this, I tried plotting t-SNE plots :
Training Domain : Test Domain :


Ok, what do you think happened here? Well, even for the training domain plot, there is a blurry boundary between class A and class C. For test domain, the model does seem to have separated class A and C (green and blue) to a certain extent, but is not able to draw a boundary at the right place. I think it is taking most of the circle including the blue dots included as class A.
Now I can think back to the data formation stage and see what mistakes I could have made there. When I scraped images of class A from Google, without noticing I could have included some images that have similar characteristics as class C (that did not overlap with class B). For example, let's say class A is "avocado" and class C is "knife". I would have scraped a bunch of google images with search keywords "avocado" and "knife", and used them for my training. But what if some images of avocado included a small knife slicing it? I did go through the step of looking at all images and deleting unrelated ones (like an image of avocado smoothie). Maybe I missed some avocado images with a knife present, because I was focusing on the avocado. This is really where the human error is introduced in machine learning.
Machine learning models are EXTREMELY sensitive to incoming data distribution. It will most likely to succeed in classifying data with a similar distribution with the training data. So the next step will be to carefully review the images again to see what characteristics could overlap between class A and class C. If needed, I will also scrape more images the two classes, while making sure that those overlapping characteristics are not present. Isn't this a great improvement from a usual "Omg this model's sh*t! I should bump it up to a ResNet-101"? :D
Self-Reflection :
I learned that I need to present the model with images of classes that have clear distinctions. For a machine learning model, the data I give it IS its whole world. I cannot expect it to have the same level of knowledge and robustness that I have about perceiving world, with 20+ years of non-stop image-classification experience.



Comments